Structural biology and AlphaFold


Structural biology delves into fundamental biological structures such as proteins, DNA, and RNA, examining their behaviors, formations, and conformations. The integration of structural biology with AI has opened numerous avenues, including predicting 3D structures of proteins and simulating interactions, thereby advancing fields like omics biology in general and medicine 3.0, artificial drug discovery in particular. Among these challenges, protein folding—understanding how proteins fold and predicting the folding patterns of unknown proteins—stands out as a very fundamental problem. Accurate predictions can accelerate biological research by minimizing wet lab tests and escalating the usage of dry and soft research tools. DeepMind's AlphaFold models, particularly AlphaFold 2, have made groundbreaking strides in this area, achieving accuracies exceeding 90% in protein structure predictions. This achievement was recognized with the 2024 Nobel Prize in Chemistry awarded to Demis Hassabis and John Jumper of DeepMind, alongside David Baker of the University of Washington, for their pioneering work in AI-driven protein structure prediction and computational protein design.
This blog post aims to help fellow readers understand the significance of secondary and tertiary structure of protein and folding in general. How does a protein fold? How does it even form in the first place? What’s the relationship between structures like DNA, RNA, and proteins—and why is this trio one of the most fundamental building blocks of what we call life? Tighten your seatbelts, because we’re about to uncover the answers to these questions one layer at a time.
How do Proteins form
Well, lot of us tech bros only care about proteins to gain good muscle lol. But if you think about it, every living organism right from tiniest bacteria to humans is fundamentally run by some macro and supra molecules like DNA, DNP (Deoxy Ribo Nucleo protein), RNP (Ribo Nucleo Protein), Enzymes etc. They do everything (like literally everything) from providing structure to cells, catalyzing reactions, transmitting signals, defending our body against invaders (like diverse pathogen, likeVirus) etc. In the end each of the proteins and how they work is just some set of massive chains of biochemical reactions. However they are fascinating. Now the question comes how and from where does protein originates? In one word, It all starts with DNA (the instruction manual of life). Let’s brush up our high school knowledge about cells and take a roller coaster ride right from cells to DNA.
We are on a mission to make molecular and structural biology related experiments easier than ever. Whether you are doing research on protein design, drug design or want to run and organize your experiments, LiteFold helps to manage that with ease. Do try out, it's free.
A small rollercoaster ride of Analogies
Since I expect most readers here have very little background in biology, let’s start from the basics. You probably know this: every living organism is made up of cells. Now, inside a cell, we have the nucleus.
Inside the nucleus, there are tiny openings called nuclear pores—think of them as selective gates that allow specific molecules to enter and exit.
Within the nucleus, we find chromosomes. Chromosomes are essentially highly organized, tightly coiled structures made up of DNA wrapped around histone proteins (imagine threads wrapped around tiny spools).
DNA, or deoxyribonucleic acid, is this long, twisted molecule (a double helix, if you remember) that carries all the genetic instructions needed to build and operate an organism. Specific sections of the DNA that actually do something meaningful are called genes (we’ll come back to this later).
Within the nucleus, we find chromosomes. Chromosomes are essentially highly organized, tightly coiled structures made up of DNA wrapped around histone proteins (imagine threads wrapped around tiny spools).

DNA, or deoxyribonucleic acid, is this long, twisted molecule (a double helix, if you remember) that carries all the genetic instructions needed to build and operate an organism. Specific sections of the DNA that actually do something meaningful are called genes (we’ll come back to this later).
Now, programmatically, you can think of DNA as the main gateway to a massive, ancient codebase. Some parts of this codebase make perfect sense, while other parts are just commented-out, outdated, or gibberish lines of code that don’t seem useful at all. The meaningful, functional parts of the codebase are what we call genes.
And here's another fun analogy: think of genes like classes in object-oriented programming. A class acts as a blueprint for creating objects; similarly, genes are blueprints for making proteins. Now, just like how we instantiate an object from a class, we instantiate something called mRNA from a gene.
And just like how you use objects to perform different functions in a program, mRNA is used as the working copy to build proteins. The process of creating mRNA from DNA is called transcription, and the process of creating proteins from mRNA is called translation.
Time to dive deeper to Transcription
Now let’s dive deeper into how proteins form and fold. As we know, DNA is the starting point for creating proteins. DNA is massive in length, but most of it “does not make sense” in terms of coding for proteins. The sections of DNA that contain useful information are called genes (see the image below).
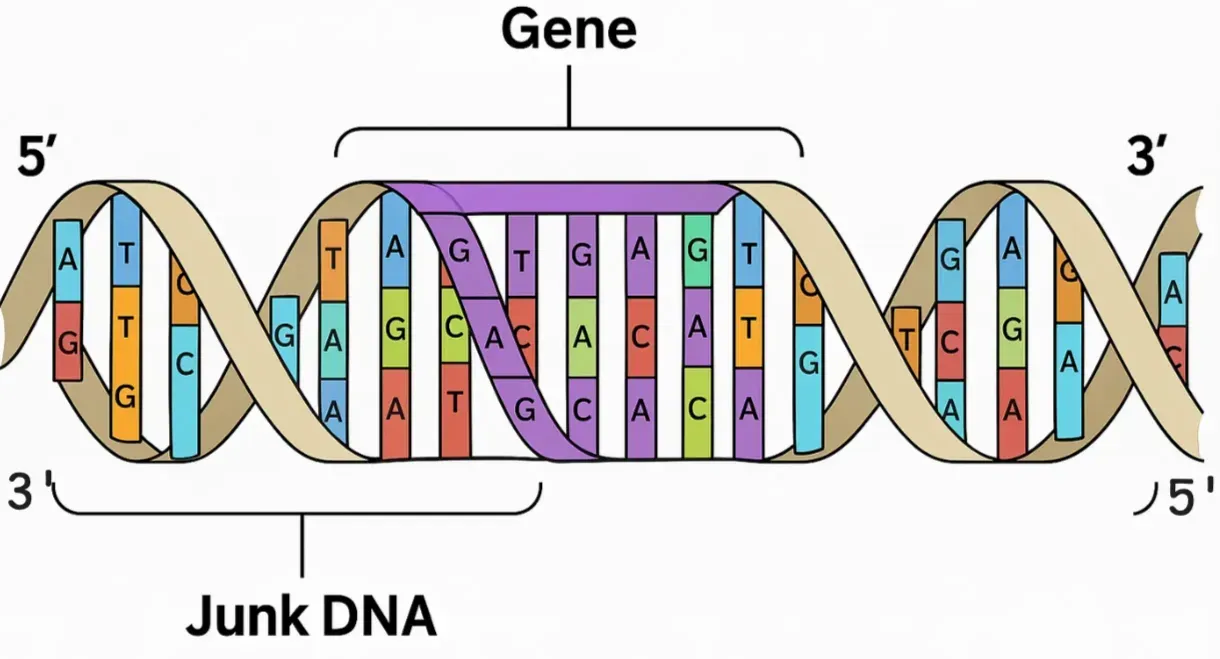
Above is a simplified structure of DNA. The four letters you see here—A, T, C, G—are called nucleotides. A stands for Adenine, T for Thymine, C for Cytosine, and G for Guanine. These are complex chemical structures where A always pairs with T (through two hydrogen bonds), and C always pairs with G (through three hydrogen bonds). The 3’ and 5’ marks indicate the direction of the strands. You can think of DNA like a coiled zip, where one strand (from 3' to 5') is the sense strand, and the other (from 5' to 3') is the antiparallel strand (behave as anitsense strand). These are useful as you will see in the next section.
We begin with the process of transcription, which takes place inside the nucleus. During transcription, a protein called RNA polymerase binds to the DNA and unwinds it, causing the double helix to "unzip." RNA polymerase then starts “parsing” the DNA from the 3' to 5' direction. In the process, it synthesizes a single-stranded structure known as mRNA (messenger RNA).

We begin with the process of transcription, which takes place inside the nucleus. During transcription, a protein called RNA polymerase binds to the DNA and unwinds it, causing the double helix to "unzip." RNA polymerase then starts “parsing” the DNA from the 3' to 5' direction. In the process, it synthesizes a single-stranded structure known as mRNA (messenger RNA).
This mRNA is complementary to the DNA template strand and is synthesized in the 5' to 3' direction. As you can see in the gif above, the purple-yellow double coiled structure is DNA and a single coiled structure is the mRNA. The big-blob like structure is our RNA polymerase. One fun fact, it’s interesting on how RNA polymerase finds where to start and where to end.
A fun fact: It's interesting how RNA polymerase knows where to start and stop. If you're familiar with tokenization in LLMs, it's similar to how we have special tokens like <BOS> and <EOS>. In DNA, specific sequences called promoters signal where RNA polymerase should begin, and terminators mark the end, guiding the process just like special tokens in LLMs. mRNA or messenger RNA is a coiled single stranded structure.
Just like DNA, RNA consists mainly of the four letters A, G, C, and U. Notice that instead of T (Thymine), we have U (Uracil), which is a key differentiator between RNA and DNA in terms of chemical structure. Similar to mRNA, another type of RNA called tRNA (transfer RNA) is also formed during transcription, and we'll explore its function later. The point is, each type of RNA has a unique structure and shape that enables it to perform specific functions.
Before protein synthesis begins, there's an interesting step right after RNA is formed. The early transcribed RNAs, like mRNA and tRNA, are called nascent RNA, meaning they are unstable. When RNA polymerase parses the DNA, it doesn't distinguish between gene sequences and non-coding (junk) DNA.
It simply makes a single pass. As a result, the mRNA that forms is nascent and includes both functional and non-functional parts. To fix this, a protein called spliceosome comes in and removes the non-coding regions (introns) of the mRNA. After this splicing, we have a fully functional mRNA (exons) that’s ready for protein synthesis.

Before moving forward, please note that: structures like mRNA or tRNA are not really a single thread like structure. Rather they are complex molecular structure which are itself 3D in shape (unlike all other molecules). However there shape matters a lot. For instance, here is how different RNA looks like.
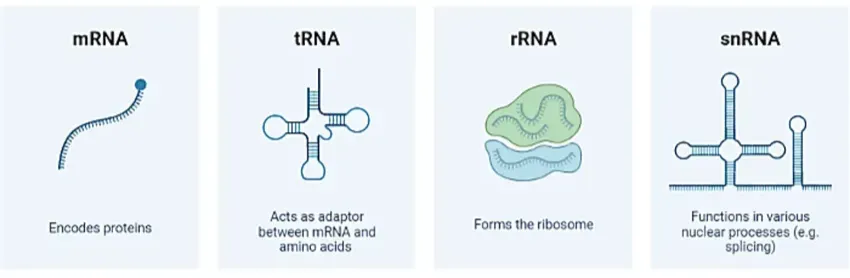
These are just some quite a handful of RNAs I have shown. However I assume you got the idea here. These shapes are very much significant which we will uncover more in the next section.
Great job if you have understood till here now. If not, then I highly encourage you to watch this 2 mins video which simulates the process of transcription and translation. More on translation on the next section.
Translation: Journey from RNA to Protein
Once the RNA molecules are synthesized and processed, they need to exit the nucleus to reach the cytoplasm where protein synthesis occurs. This transport happens through specialized channels in the nuclear envelope called nuclear pores. Only properly processed RNA, especially mature mRNA, is allowed to pass through these pores, ensuring that only functional transcripts enter the cytoplasm.
Inside the cytoplasm, the mature mRNA associates with Ribosomes (a Ribosome is composed of complex molecular structures like Ribosomal RNA and proteins). Pay attention to figure 5 from our previous section. Notice how mRNA looks like a single strand, tRNA looks like a hair pin (or clover leaf), rRNA looks like a blob where you can fit something. These are very important.
Ribosome (made up with these rRNA) tries to “read” the sequences of the mRNA in set of three nucleotides called codons.

Each codon will code for one amino acid (proteins are just a chain of amino acid). So picture this, the mRNA binds with the ribosome which is “parsing” mRNA in the set of 3 sequences each. On the other side tRNA brings the amino acid and sits on each codon. tRNA has an anticodon region which sits on top of mRNA codons (an anticodon is a codon but with complementary sequence. For example; if AUG is a codon then UAC is the anticodon).

So like this with each pass of “parsing” the mRNA sequence (set of 3), each amino acid gets linked with each other form a chain. And this will not stop till the stop codon is reached. Again you can think it like when a LLM reaches the stop token, then it no more generates a new token. Below is a simple GIF that shows how the process of translation takes place.
Awesome, that’s pretty much it. We now know how exactly transcription followed by translation works. As you can see that, chain of amino acids gets linked with each other like beads of necklace. However once the process of translation stops, the chain of amino acid goes out of the Ribosome. The initial nascent protein undergoes into lots of conformational changes which turns it into a three dimensional structure. We will discuss more about it in the next section.
Folding
We are almost there. The linear nascent chain of amino acid formed just after translation is not functional yet. This current structure state is called primary structure of a protein. Beads of amino acid linked with peptide bonds. The folding starts to happen in many cases mostly driven by chemical properties like van-der-wals forces, electrostatic forces etc. As soon as amino acid starts to fold it forms repeated patterns stabilized by hydrogen bonds. There are two such types of structure:
- Alpha helices (α-helices): Coiled structures like a spring
- Beta sheets (β-sheets): Flattened, sheet-like structures formed when segments of the chain align side by side.
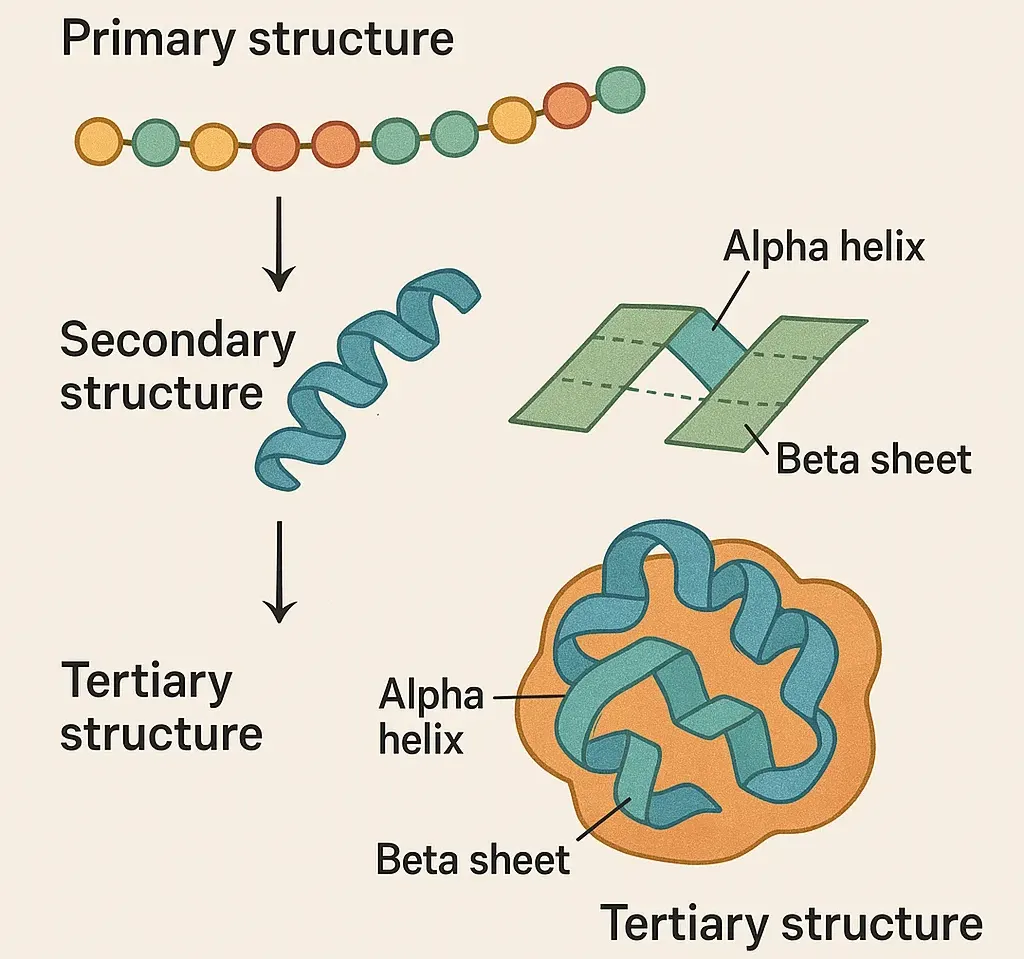
These local structures gives the protein initial stability and helps to form the overall shape. This structure state is called secondary structure. Finally these secondary structure further folds into 3D globular shape due other various types of interactions like Hydrophobic interactions, Hydrogen bonds, Ionic bond etc. In the end this series of chemical interactions happens to make the large molecules undergo to a state of equilibrium. Very simply in AlphaFold, we will be given the series of amino acid (kinda like the primary structure) and we need to predict the tertiary structure out from it.
Structure is everything
In the end, structure is everything. It is the fundamental factor that determines how a complex system looks and functions. Think about it — coal and diamond are made of the exact same element, carbon, yet they have completely different physical properties. One is brittle, the other is incredibly hard. The difference lies purely in how the carbon atoms are arranged structurally.
Similarly, in biology, biomolecules like DNA, RNA, enzymes, or any kind of protein must have the correct shape to function properly and interact with other molecules. For example, enzymes are often called biochemical catalysts because they speed up chemical reactions by lowering activation energy. But how exactly do they do it?
The answer again lies in structure: every enzyme has a specific three-dimensional shape that allows it to bind precisely to its target molecule (substrate), facilitating the reaction. The substrate (i.e. our target molecule) fits into the active site like a key fits into a lock (also called as lock-and-key model). Once bound, the enzyme and the substrate undergoes a chemical reaction making a new product.
AlphaFold2
As mentioned previously, for the very first time in history, the Nobel Prize has been awarded to an AI-native solution in the field of chemistry. That’s a huge deal. The prize was awarded for solving a decades-old problem, predicting the 3D structure of a protein from its amino acid sequence, a task known as the protein folding problem. The name of this groundbreaking project? AlphaFold2 by Google DeepMind.
In simple terms, Given a sequence of amino acids (i.e., the primary structure), can we predict how it folds into its final 3D shape (i.e., the tertiary structure)? And not just "kind of guess it", but predict it with near-experimental accuracy — something biologists have dreamt of for decades.
AlphaFold2 treats this as a geometry prediction problem guided by biological constraints. It leverages Transformers (yes, the same ones behind LLMs) to understand spatial relationships between amino acids and predicts pairwise distances and angles, iteratively refining them through a mechanism called recycling. It doesn’t simulate the physics directly like old-school methods; instead, it learns structure implicitly from huge datasets of known protein structures and alignments.
At its core, AlphaFold2 is a highly intricate attention-based architecture that encodes both sequence and spatial relationships — making it a perfect blend of bio + geometry + deep learning. We will learn more about AlphaFold2 details in the coming blog posts.
Conclusion
Congratulations , you now have enough domain knowledge to not be afraid of tackling the protein folding problem. In our next blog post, we’re going to take a brief look at the current state of protein folding powered by deep learning. We’ll dive into some key bio-computational literature that will help us navigate more complex ideas with confidence. Along the way, we’ll explore different types of architectures that have contributed to breakthroughs in protein structure prediction.